商户查询缓存
缓存的定义
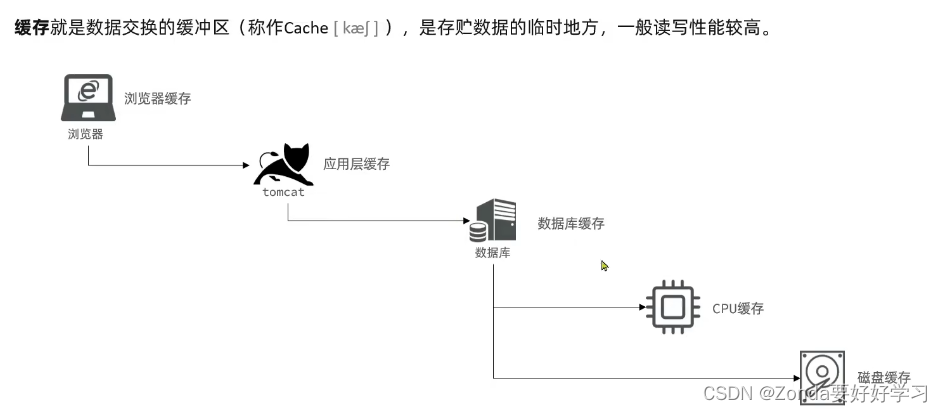
缓存就是数据交换的缓冲区(Cache),是存储数据的临时地方,一般读写性能较高。
- 比如计算机的CPU计算速度非常快,但是需要先从内存中读取数据再放入CPU的寄存器中进行运算,这样会限制CPU的运算速度,所以CPU中也会设计一个缓存,存入经常需要用到的数据,提升了运算效率。CPU缓存也是衡量CPU性能好坏的重要标准之一。
- 再比如浏览器缓存,会缓存一些页面静态资源(js、css),浏览器缓存未命中的一些数据就会去Tomcat中的Java应用请求,而Java应用也有应用层缓存,一般用Redis去做。如果缓存再没有命中,就可以去数据库查询,数据库也有缓存,mysql中如索引数据。最后还会去查询CPU缓存,磁盘缓存。
缓存的优缺点
优点:
缺点:
给店铺查询任务添加缓存
整体的业务逻辑如下图所示:
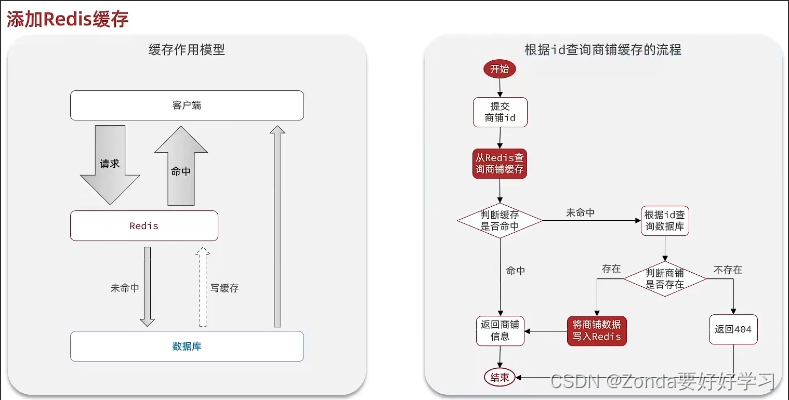
- 先从redis中通过店铺id查询缓存数据,登录模块是用map存的,这里我们使用String来存,就需要将对象先转为JSON格式。
- 如果redis中存在,就返回店铺信息。
- 如果redis中不存在,就继续向数据库中查询。
- 如果数据库不存在,返回“店铺不存在”
- 如果数据库存在,将店铺信息写入redis
- 返回店铺信息
代码如下:
package com.hmdp.service.impl;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.hmdp.mapper.ShopMapper;
import com.hmdp.service.IShopService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import static com.hmdp.utils.RedisConstants.CACHE_SHOP_KEY;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
//1.从redis中查询
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.存在,返回店铺信息
if (!StringUtils.isBlank(shopJson)) {
return Result.ok(JSONUtil.toBean(shopJson, Shop.class));
}
//3.不存在,用id在数据库查询
Shop shop = getById(id);
//4.不存在,返回“店铺不存在”
if (shop == null) {
return Result.ok("店铺不存在");
}
//5.存在,缓存到redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
//6.返回店铺信息
return Result.ok(shop);
}
}
然后再去第二次查询某一个美食的数据,发现速度由2ms变成了1ms。
在resp中也发现了cache:shop:id的缓存。
拓展练习
将首页的店铺种类信息缓存到redis中

因为店铺种类有十种,可以通过LIst的数据结构存储,但是需要将List中的ShopType对象先转为JSON,取出的时候再由JSON转为ShopType对象。具体代码如下:
package com.hmdp.service.impl;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.dto.Result;
import com.hmdp.entity.ShopType;
import com.hmdp.mapper.ShopTypeMapper;
import com.hmdp.service.IShopTypeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import static com.hmdp.utils.RedisConstants.CACHE_SHOP_TYPE_KEY;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {
@Autowired
StringRedisTemplate stringRedisTemplate;
public Result queryTypeList() {
//1.从redis中查找店铺类型数据
List<String> shopTypesByRedis = stringRedisTemplate.opsForList().range(CACHE_SHOP_TYPE_KEY, 0, 9);
//2.存在,返回店铺信息,最终需要返回List<ShopType>形式的list,因此需要将JSON转换为ShopType类型
List<ShopType> shopTypes = new ArrayList<>();
if(shopTypesByRedis.size() != 0){
for(String s:shopTypesByRedis){
//转为JSON
ShopType shoptype = JSONUtil.toBean(s, ShopType.class);
shopTypes.add(shoptype);
}
return Result.ok(shopTypes);
}
//3.不存在,去数据库中寻找,并根据sort排序
List<ShopType> shopTypesByMysql = query().orderByAsc("sort").list();
//4.数据库不存在,返回店铺信息不存在
if(shopTypesByMysql.size() == 0){
return Result.ok("店铺信息不存在");
}
//5.店铺信息存在,存入redis中
for(ShopType shop:shopTypesByMysql){
stringRedisTemplate.opsForList().leftPush(CACHE_SHOP_TYPE_KEY, JSONUtil.toJsonStr(shop));
}
//6.返回店铺信息
return Result.ok(shopTypesByMysql);
}
}
缓存更新策略
在业务中,如果我们对数据库数据做了一些修改,但是缓存中的数据没有保持同步更新,用户查询时会查到缓存中的旧数据,这在很多场景下是不允许的。缓存更新的几种策略有三种:
- 内存淘汰(该机制默认存在)
缓存设定一定的上限,当达到这个上限就会自动淘汰部分数据。一致性保持较差,因为淘汰的这一部分数据才可以更新,维护成本为0. - 超时剔除
通过redis中的expire关键字添加TTL时间,到期后自动删除缓存。
一致性强弱取决于TTL的时间,一致性一般好于内存淘汰机制。维护成本也不是很高。 - 主动更新 <\font>
自己编写业务逻辑,在修改数据库的同时,更新缓存。
一致性好,但是维护成本较高。
业务场景选择更新策略的原则:

主动更新的方法可以采用:当数据库发生改变的时候,删除缓存,当查询数据库的时候,更新缓存。
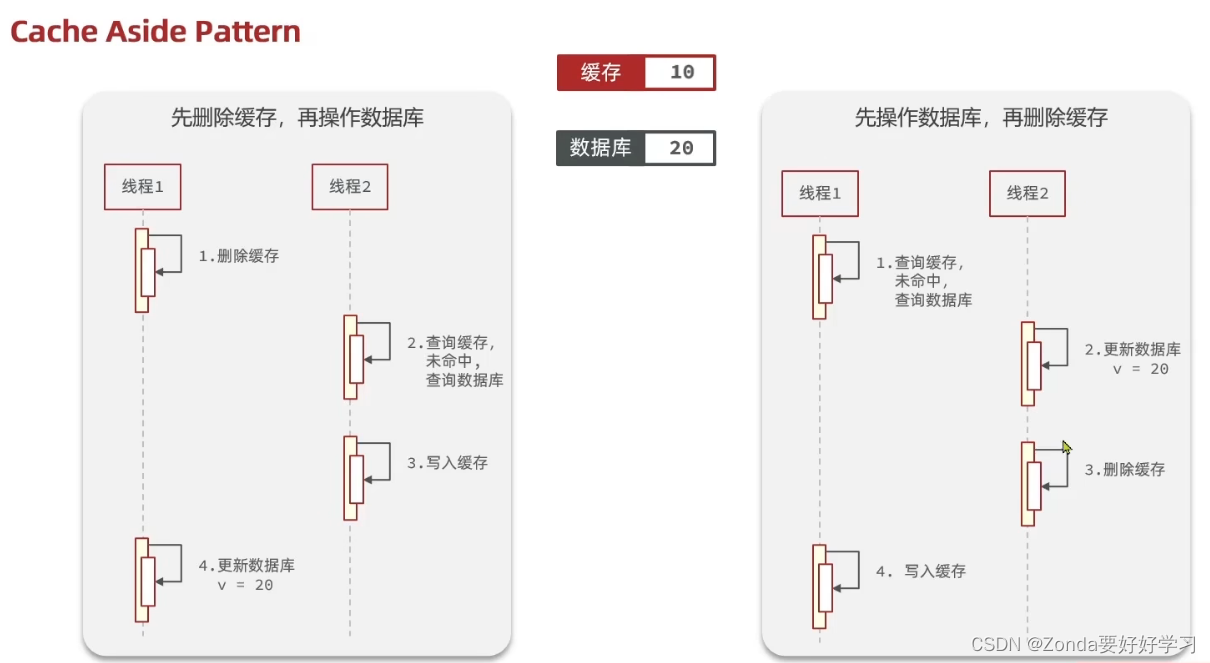
这里有两种操作顺序的选择:
- 先删除缓存,再操作数据库,但是有可能发生如下图左图的安全问题。
- 先操作数据库,再删除缓存。有可能发生如下图右图的安全问题。
- 但是因为数据库读写时间远远大于缓存读写时间,因此右图发生的概率更低。万一发生,超时时间可以兜底。
业务修改
//5.存在,缓存到redis,加入有效时间限制
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
- 根据id修改商铺信息,先修改数据库,再删除缓存。这两个动作需要绑定,所以该方法用事务控制其原子性。
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if(id == null){
return Result.fail("店铺id不为空");
}
//1.更新数据库
updateById(shop);
//2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY+shop.getId());
return Result.ok();
}
测试:
- 首先测试当访问某一家店铺信息的时候,未命中,是否会缓存到redis中
- 再测试修改店铺信息是否会删除redis缓存,因为修改的功能只能在商家界面做,所以这里用http-client对业务逻辑进行测试。==发送请求,数据库修改,redis缓存也被删除。==说明业务修改成功。这样可以有效解决一致性问题。
PUT http://localhost:8081/shop
Content-Type: application/json
{
"area":"大关",
"openHours": "10:00-22:00",
"sold": 4215,
"address": "china",
"comments":3035,
"avgPrice": 80,
"score": 37,
"name": "110茶餐厅",
"typeId": 1,
"id": 1
}
缓存穿透
客户端请求的数据在缓存和数据库中都不存在,那么根据我们的缓存更新策略,最终都会向数据库索取数据;那么如果有不怀好意的人用并发的线程用虚假的id向数据库请求数据,就会搞垮数据库。
两种解决方案:
- 缓存空对象:如果redis和数据库中都未能命中,最终数据库会向redis写入一个null,这样在下一次向redis请求的时候就不会再到达数据库。
优点:实现简单、维护方便
缺点:- 有额外的内存消耗(但是也可以给null设置一个TTL)
- 可能造成短期的不一致(可以控制TTL的时长)
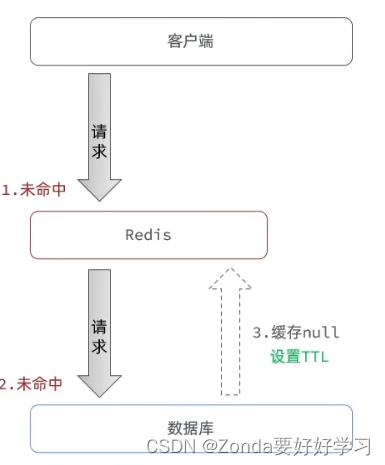
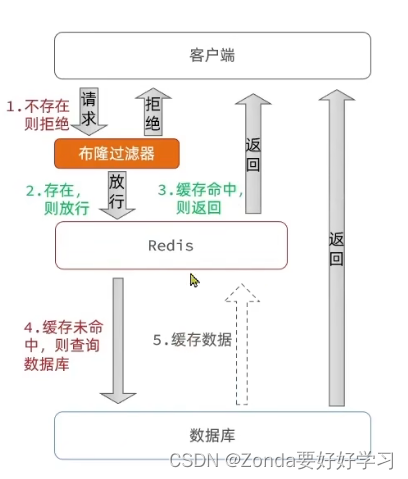
- 布隆过滤器
- 布隆过滤器的原理:
- 定义:布隆过滤器(Bloom Filter)是一种空间效率非常高的概率型数据结构,用于判断一个元素是否属于某个集合。
- 构成:
1.布隆过滤器使用一个固定长度的位数组,所有位初始都设置为0。
2.一组独立的哈希函数,用于将输入元素映射到位数组中的某个位置。 - 判断原理:向布隆过滤器中添加元素时,通过k个哈希函数计算出k个位置,并将这些位置上的位设置为1。查询元素时,使用同样的哈希函数计算出k个位置,并检查这些位置上的位是否全为1。如果所有位置都为1,则元素可能在集合中;如果有一个位置为0,则元素肯定不在集合中。
- 优点:内存占用小,没有多余的key
- 缺点:实现复杂、存在误判可能
- 布隆过滤器的原理:
采用缓存空对象解决缓存穿透问题
我们应该做如下修改:
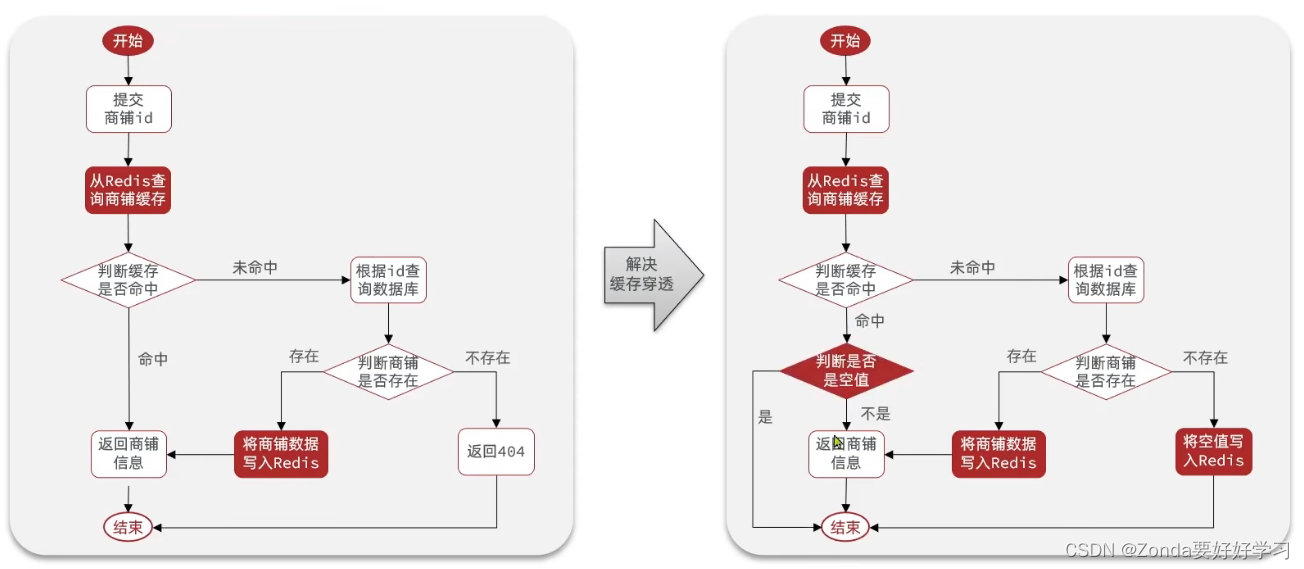
我们需要修改queryById方法,注意字符串判断内容是否相等用equals:shopJson.equals(“”)
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
//1.从redis中查询
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.命中,返回店铺信息
if (!StringUtils.isBlank(shopJson)) {
return Result.ok(JSONUtil.toBean(shopJson, Shop.class));
}
//如果命中的是"",就返回"店铺信息不存在!"
if(shopJson != null){
return Result.fail("店铺信息不存在!");
}
//3.不存在,用id在数据库查询
Shop shop = getById(id);
//4.不存在,返回“店铺不存在”
if (shop == null) {
//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"
stringRedisTemplate.opsForValue().set(key, "");
return Result.ok("店铺信息不存在!");
}
//5.存在,缓存到redis,加入有效时间限制
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
//6.返回店铺信息
return Result.ok(shop);
}
然后进行测试,发送请求:http://localhost:8080/api/shop/1111,id=1111并不存在,但是该数据会被缓存到redis中:
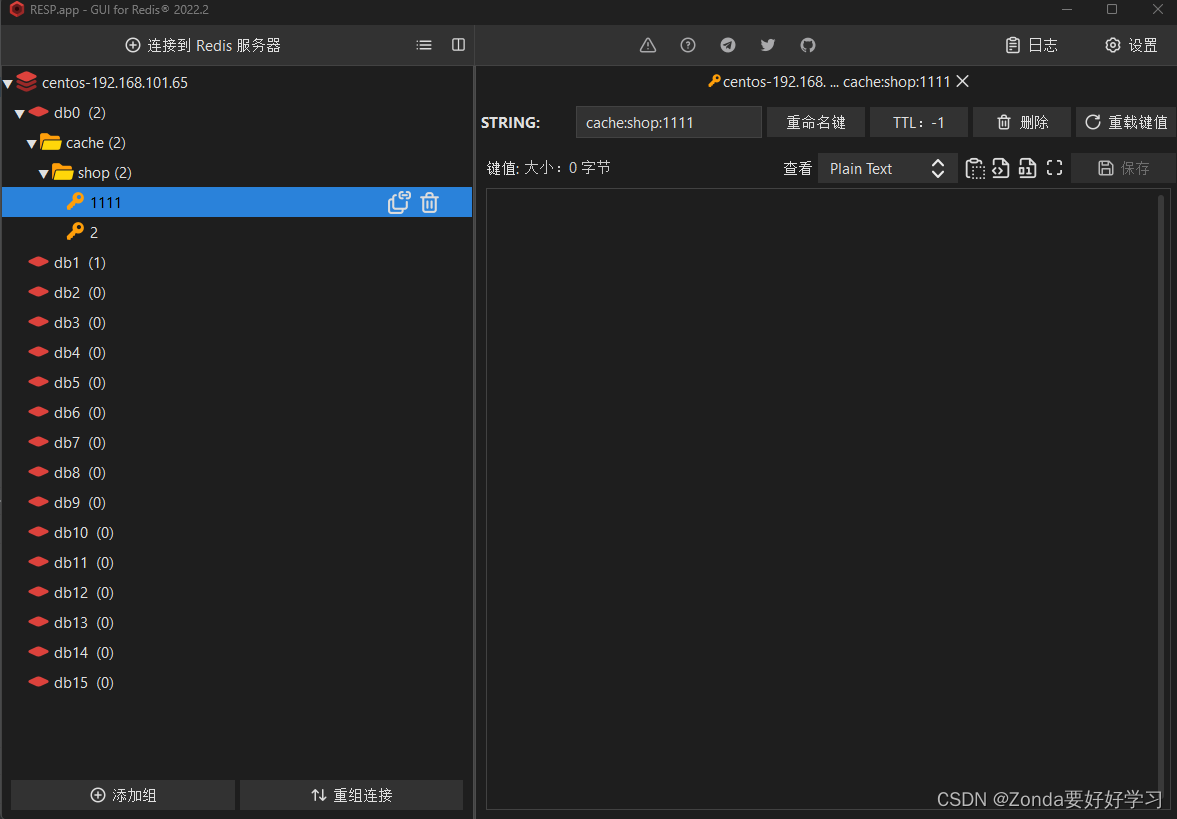 再次发送这个请求,不会到达数据库,而是访问redis之后直接就返回。控制台也没有任何数据库调用的日志打印出来。
再次发送这个请求,不会到达数据库,而是访问redis之后直接就返回。控制台也没有任何数据库调用的日志打印出来。
其他解决方案:
- 增加id的复杂度,让攻击者无发猜测到id格式。
- 对id做一些基础的格式校验
- 加强用户权限的管理
- 做好热点参数的限流
缓存雪崩
缓存雪崩指的是大量可以在同一时段同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
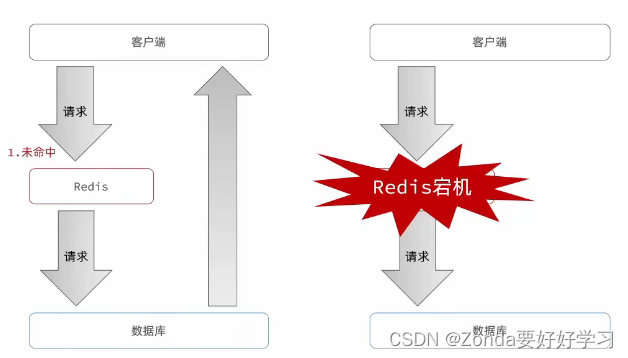
解决方案:
- 给不同的key的TTL添加随机值,这样key就不会在同一时间宕机
- 提高==Redis集群(Redis哨兵模式)==服务的可用性。当一个Redis挂了,会被监控到,立马启动另外一个Redis提供服务。也可以使用主从结构构成集群,防止主节点的数据丢失。
- 给缓存业务添加降级限流策略(比如快速失败、拒绝服务)
- 给业务添加多级缓存(Nginx缓存–JVM缓存–Redis缓存–数据库缓存)。
缓存击穿
缓存击穿也叫热点Key问题,就是一个被高并发访问(比如正在做活动的某一件商品)并且缓存建立业务较为复杂的key失效了,突然大量的请求会在瞬间给数据库带来巨大的冲击。
两种解决方案:
互斥锁解决缓存击穿
让多线程只有一个线程能获取锁来创建缓存
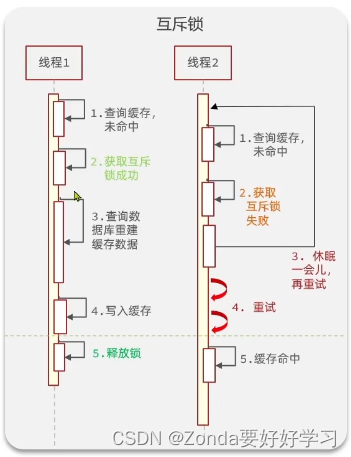
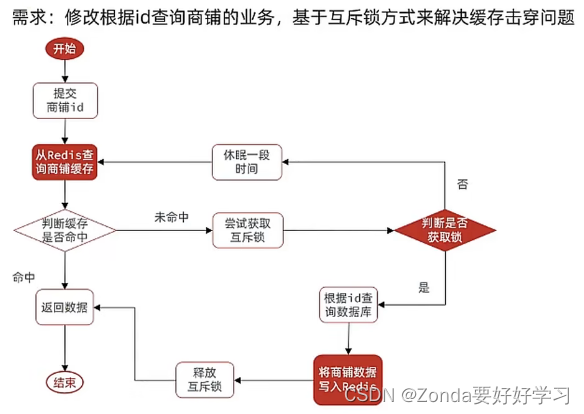
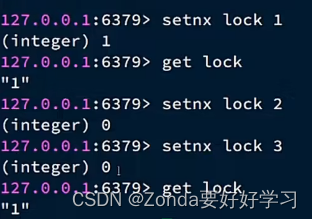
我们可以手动地设定一个锁来实现这样的功能,redis中的setnx表示只有当一个key不存在的时候才可以写入,那么这样就可以达到互斥的效果。那么,
- 获取锁的操作就是:setnx lock 1通常还会给锁加一个TTL,如果超过这个时间,就自动删除锁。防止获取到锁的线
在这里插入代码片程出问题。 - 释放锁的操作就是:del lock
代码实现: - 首先定义获取锁和释放锁的方法:
获取锁:
private boolean tryLock(String key){
//获取锁
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10L, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
释放锁:
private void unLock(String key){
stringRedisTemplate.delete(key);
}
将缓存穿透的业务逻辑封装,最终返回Shop对象
//解决缓存穿透的代码
public Shop queryWithPassThroough(Long id){
String key = CACHE_SHOP_KEY + id;
//1.从redis中查询
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.命中,返回店铺信息
if (!StringUtils.isBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
//如果命中的是"",就返回"店铺信息不存在!"
if(shopJson != null){
return null;
}
//3.不存在,用id在数据库查询
Shop shop = getById(id);
//4.不存在,返回“店铺不存在”
if (shop == null) {
//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"
stringRedisTemplate.opsForValue().set(key, "");
return shop;
}
//5.存在,缓存到redis,加入有效时间限制
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
//6.返回店铺信息
return shop;
}
用互斥锁解决缓存击穿的问题:
//用互斥锁解决缓存击穿的问题
public Shop queryWithMutex(Long id){
String key = CACHE_SHOP_KEY + id;
//1.从redis中查询
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.命中,返回店铺信息
if (!StringUtils.isBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
//3.如果命中的是"",就返回"店铺信息不存在!"
if(shopJson != null){
return null;
}
Shop shop = null;
//4.实现缓存重建
//4.1 获取互斥锁
String lockKey = "lock:shop:" + id;
boolean isLock = tryLock(lockKey);
try {
//4.2 判断是否获取成功
//4.3 失败,则休眠并重试
if(!isLock){
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4 成功,用id在数据库查询
shop = getById(id);
//5.不存在,返回“店铺不存在”
if (shop == null) {
//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"
stringRedisTemplate.opsForValue().set(key, "");
return shop;
}
//6.存在,缓存到redis,加入有效时间限制
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
//7.释放互斥锁
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally{
unLock(lockKey);
}
//8.返回店铺信息
return shop;
}
- 通过自动化测试工具jmeter对进行压力测试
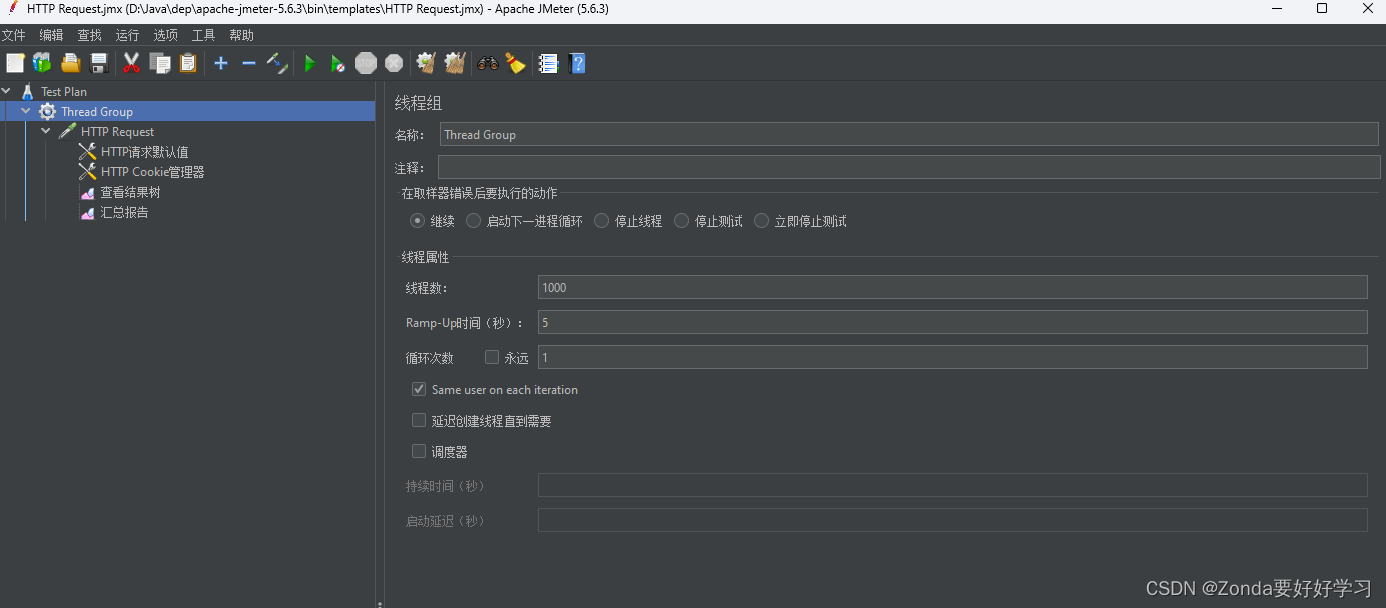
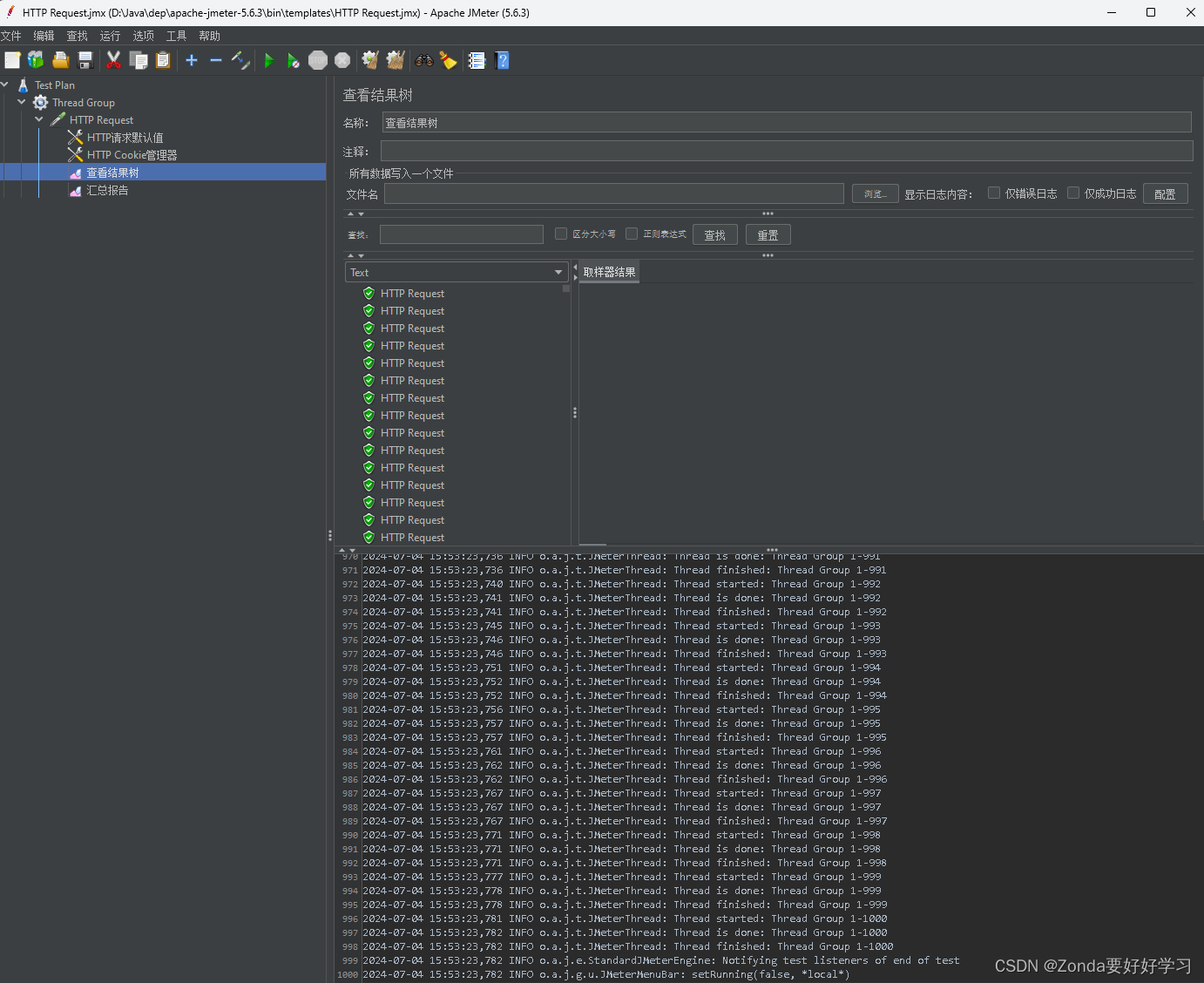
执行完发现没有报错
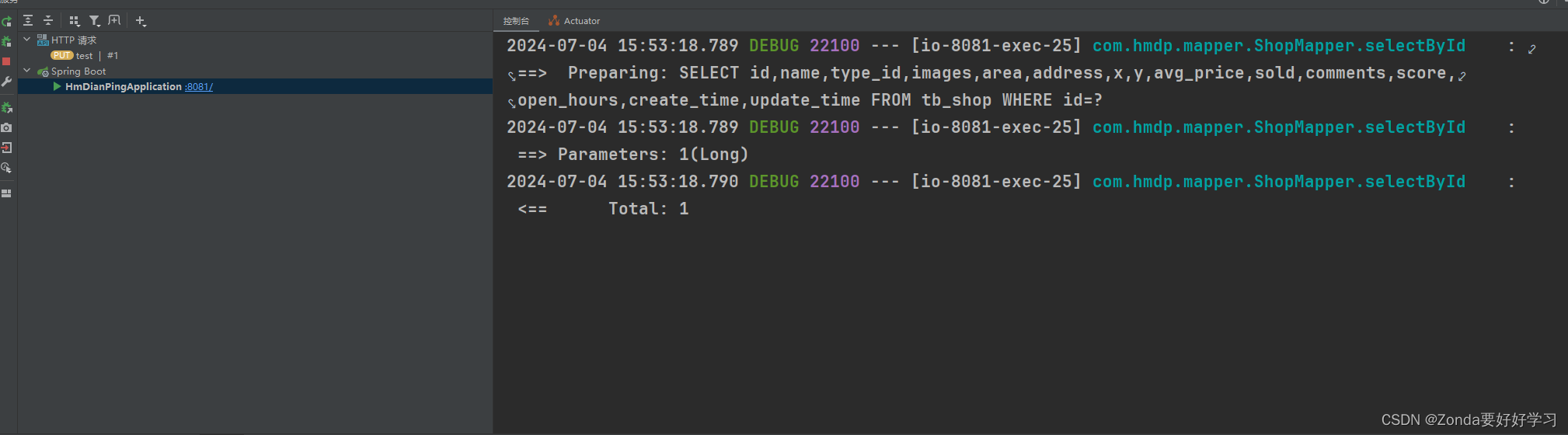
并且数据库只调用了一次select操作,说明互斥锁成功实现了
设置逻辑过期时间解决缓存击穿
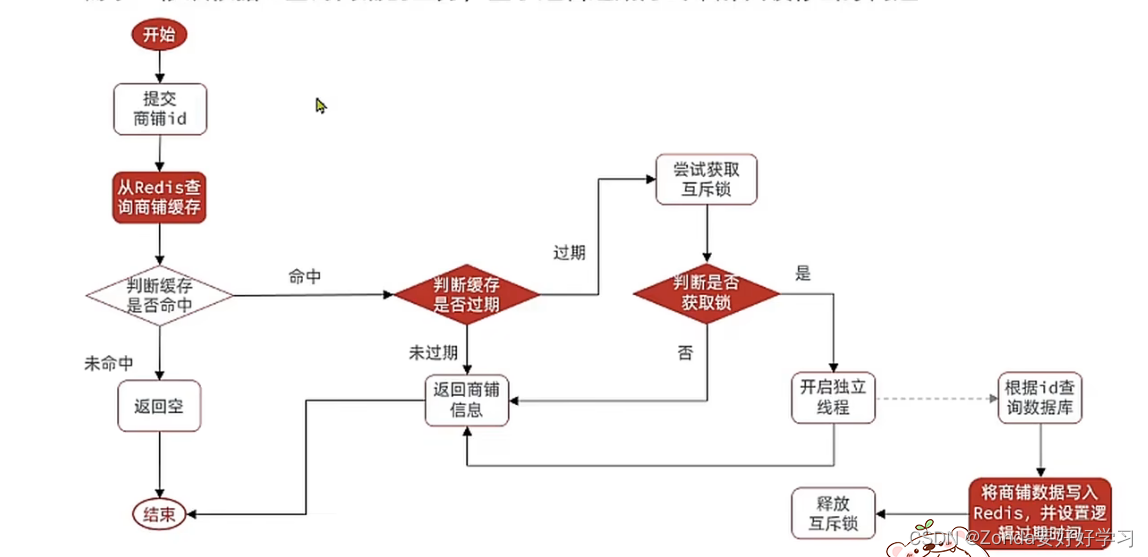
- 缓存工具封装对象:
先定义一个类用来保存以及超时时间,对原来代码没有侵入性。
package com.hmdp.entity;
import lombok.Data;
import java.time.LocalDateTime;
/**
* @author Zonda
* @version 1.0
* @description TODO
* @2024/7/4 16:21
*/
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
在ShopServiceImpl 新增此方法,利用单元测试进行缓存预热
public void saveShop2Redis(Long id,Long expireSeconds){
Shop shop = getById(id);
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}



![[leetcode]max-consecutive-ones 最大连续1的个数](https://img-blog.csdnimg.cn/direct/a5e71eccf4a04735b3a365c7d2d0d91b.png)


